Technical estimation is where strategy meets execution. It’s the conversation that turns vague ideas into actionable work with a shared understanding of size, risk, and uncertainty. Done well, it accelerates delivery and reduces rework. Done poorly, it creates hidden debt, rolling delays, and frustration.
In this guide, we’ll walk through a complete, battle-tested process for planning a technical estimate in an Agile environment—before, during, and after a Planning Poker session. You’ll learn how to prepare stories, model risk and unknowns, include non-functional requirements (NFRs), leverage technical spikes, and use your historical data to make estimation both faster and more accurate.
Our goal is not to force precision. It’s to reach a shared, realistic sense of relative size that allows better prioritization, capacity planning, and predictable delivery.

Why technical estimation matters
Technical estimation is not just about picking a number. It’s about aligning the team on scope, complexity, and risk before writing code. Alignment is what keeps initiatives flowing through the system instead of getting stuck in design gaps, integration surprises, and unplanned refactors.
When teams invest in a consistent estimation practice, three things improve quickly: (1) predictability—stakeholders get more reliable delivery windows, (2) focus—teams avoid scope creep mid-sprint, and (3) quality—NFRs and edge cases are addressed upfront instead of after release.
What makes a good technical estimate?
A good estimate reflects more than “how long to code.” It accounts for discovery, integration, testing, security, performance constraints, data migrations, and run-time readiness (observability, rollback, alerts). It also captures “unknowns” and the cost of clarifying them.
To get there consistently, we use three building blocks: (1) strong preparation (Definition of Ready), (2) a facilitation format (Planning Poker) that surfaces differences safely, and (3) post-session hygiene (syncing decisions and capturing learnings).
Preparation: Definition of Ready (DoR) for technical work
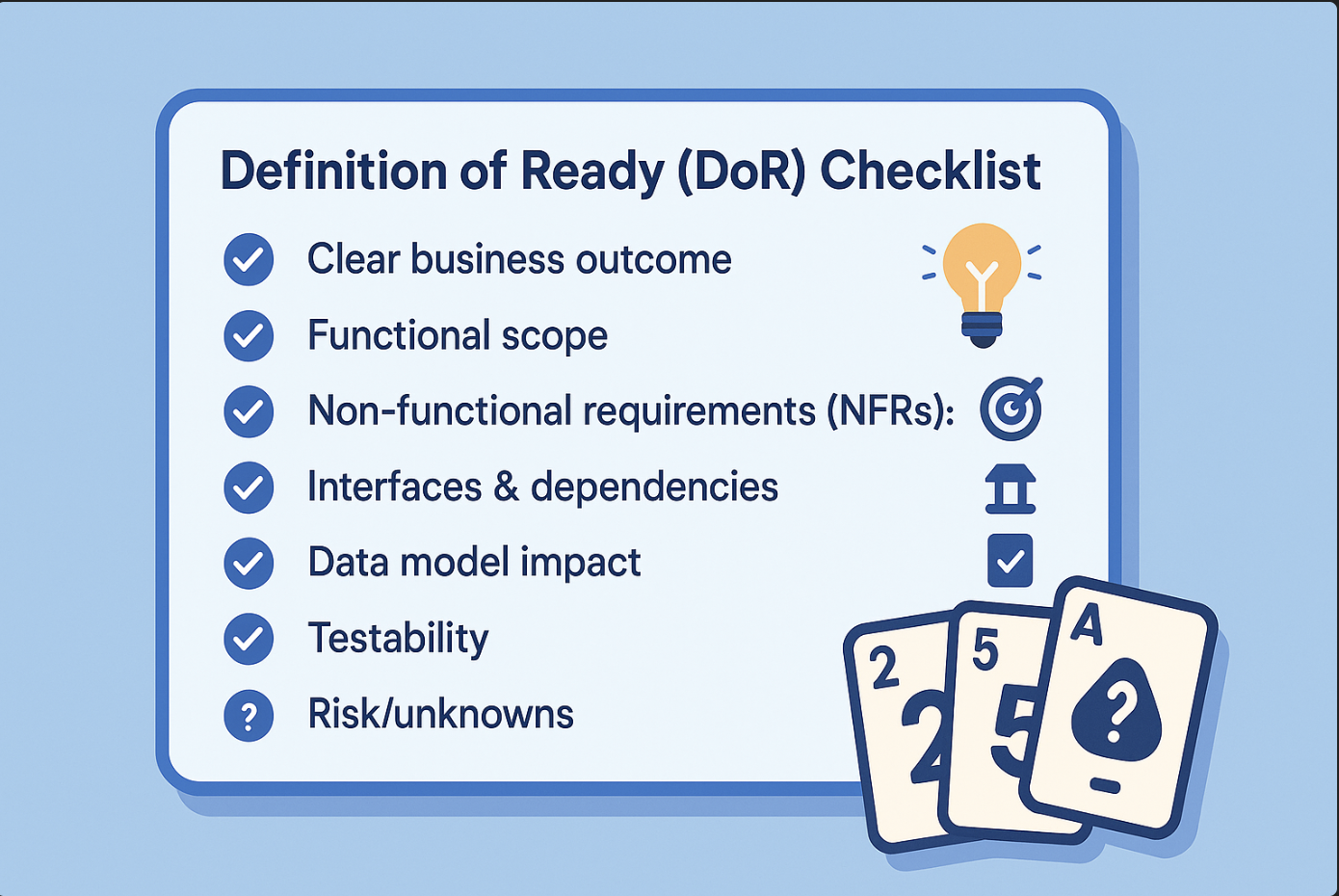
Before you estimate, ensure each story meets a minimum readiness bar. Use this DoR checklist:
- Clear business outcome (what value and who benefits).
- Functional scope with explicit in/out boundaries.
- Non-functional requirements (NFRs): performance targets, security constraints, SLAs, availability.
- Interfaces & dependencies: upstream/downstream APIs, data contracts, versioning strategy.
- Data model impact: new tables/columns, migrations, backfill needs.
- Testability: acceptance criteria, happy path, critical edge cases.
- Deployment & ops: feature flags, observability, rollback plan.
- Risk/unknowns: known gaps, decisions pending, spike needed?
Stories that miss several items should be refined or split before estimation. Estimating vague work creates false confidence.
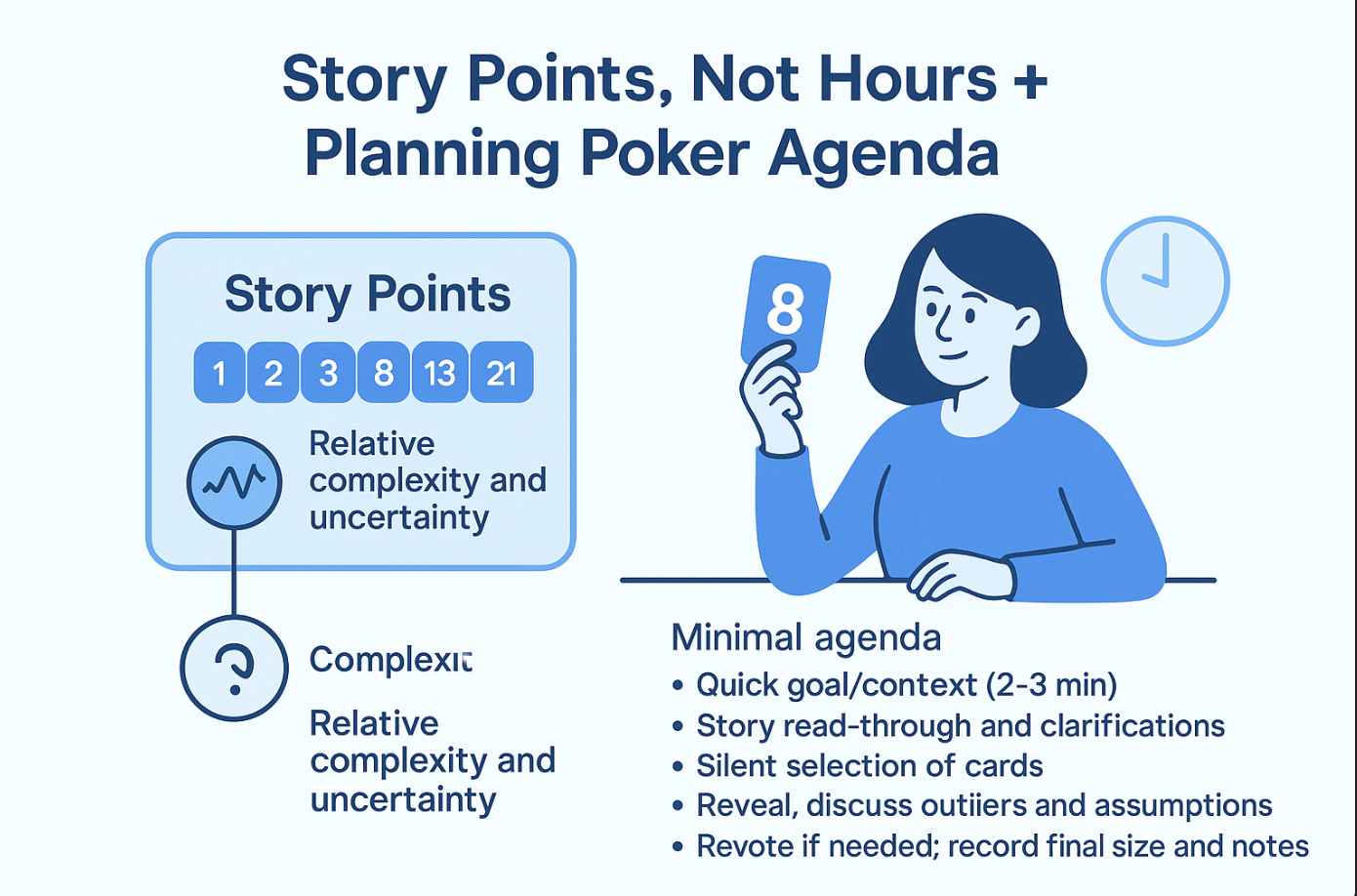
The right unit: story points (not hours)
Story points measure relative complexity and uncertainty compared to other work, using a deck like Fibonacci (1, 2, 3, 5, 8, 13, 21). Points are not hours, and trying to convert points to hours undermines the method. Hours vary by person; complexity does not.
Velocity (points completed per sprint) emerges from your team’s historical delivery. That trend—combined with current capacity—is what gives product managers and stakeholders realistic planning signals.
When to use Planning Poker
Planning Poker is ideal when you want broad participation and reduced anchoring. Everyone chooses a card privately, then reveals simultaneously. The value is not the first number—it’s the conversation that follows differences.
Minimal agenda for an estimation session
- Quick goal/context (2–3 min).
- Story read-through and clarifications.
- Silent selection of cards.
- Reveal, discuss outliers and assumptions.
- Revote if needed; record final size and notes.
- Repeat for next story.
Use a timer to keep momentum (e.g., 3–5 minutes per average story). Large disagreements often signal missing DoR items—capture a follow-up, or spin off a spike.
Incorporating NFRs and hidden work
NFRs (performance, security, reliability, accessibility, compliance) are not “nice to have”—they are part of the scope. Teams that ignore NFRs underestimate consistently and ship defects that are expensive to fix.
Embed NFRs in your acceptance criteria (e.g., “p95 latency < 300ms at 2k RPS,” “OWASP checks pass in CI,” “WCAG 2.1 AA for new UI flows,” “99.9% availability with auto-recovery”). If these are unfamiliar, raise a technical risk. Estimation must reflect the learning and hardening work.
Risk and uncertainty: modeling the unknowns
Big spreads in cards signal uncertainty. Treat uncertainty as work:
- Identify unknowns (“Can our auth service handle this flow?” “How dirty is the legacy data?”).
- Translate the top unknowns into spikes (time-boxed research tasks) and estimate those separately.
- Adjust the main story size to include the integration cost and stabilizing effort you now understand.
A practical rule: if team discussion produces ≥3 substantive unknowns, add a spike instead of inflating the base story. Spikes reduce risk and improve the next estimate.
Spikes: when and how to size them
Spikes are time-boxed investigations to answer a specific technical question or de-risk an integration. Examples:
- “Prototype streaming ingestion for vendor X; verify throughput and schema evolution.”
- “Measure p95 latency for new cache layer under expected traffic.”
- “Explore migration path from REST to gRPC for internal service calls.”
Keep spikes small (typically 3–5 points) and concrete: they must end with an artifact (doc, PoC branch, metrics, decision). Spikes that produce reusable code can become partial delivery stories.

Example: splitting a large technical story
Original story: “Rebuild the customer notifications pipeline to support SMS + push with idempotency.” The team senses it’s huge and uncertain.
Split pattern:
- Spike: “Evaluate provider SDKs + throughput; prove idempotent design with Redis keys.”
- Story 1: “Introduce generic event schema + topic routing.”
- Story 2: “Implement SMS provider integration with retries + DLQ.”
- Story 3: “Implement push provider integration with dedupe + observability.”
- Story 4: “Rollout plan + feature flag + canary + dashboards.”
This decomposition clarifies scope, reduces risk, and makes estimates meaningful.
Data-driven estimation: use your history
Estimation improves when you learn from your own data. Pull these signals from prior sprints:
- Median and p95 cycle time for stories sized 3/5/8/13.
- Defect rate by component (areas that routinely bite you).
- Flow efficiency (active vs waiting time) to expose process bottlenecks.
- Reopen rate after “done” (signals weak DoD or missing NFRs).
Bring those patterns into the session as heuristics: “Our 8-point data migrations with index changes usually trigger 1–2 days of tuning,” or “Stories touching module X trend one size higher due to legacy constraints.”
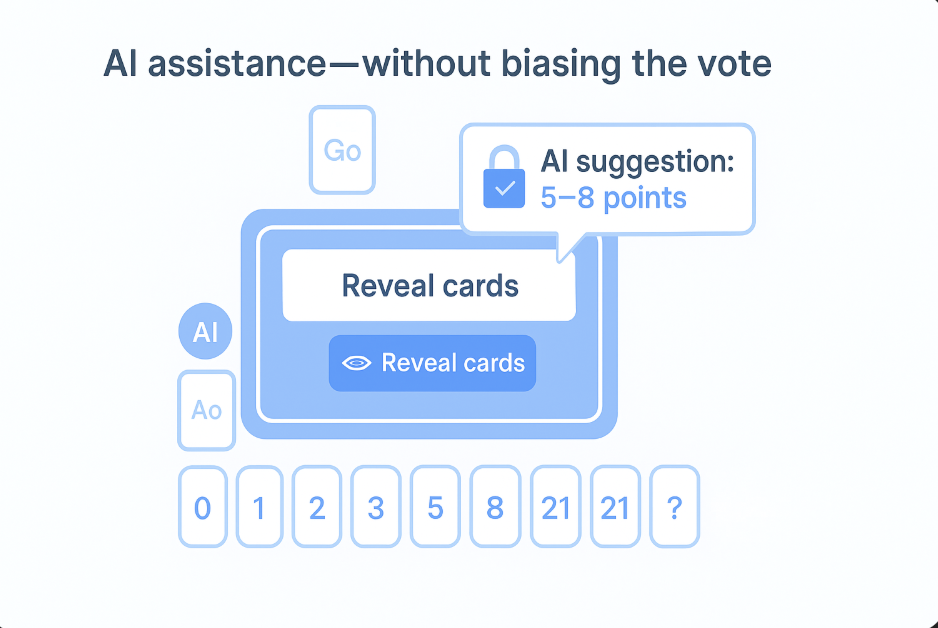
AI assistance—without biasing the vote
AI can surface talking points and suggest a size range based on similar past work. In GoAgile, keep suggestions hidden until after everyone votes to avoid anchoring. Use AI to accelerate the discussion, not to replace judgment.
Story Points vs. Hours: the healthy boundary
Your stakeholders will ask for dates. That’s normal. Translate velocity + capacity into a forecast—not by converting points to hours, but by using what your team actually finishes per sprint.
Example: if your team’s steady velocity is 32–36 points and you have 72 points of prioritized work, plan for ~2 sprints with buffer for risk. If you have known uncertainty, protect the plan with a capacity buffer instead of inflating point estimates.
A lightweight estimation playbook
- Before the session: ensure DoR, mark dependencies, prep data model changes, define NFRs, and tag “needs spike.”
- During the session: Planning Poker with a timer; reveal → discuss → capture decisions; spin off spikes as needed.
- After the session: sync final sizes to Jira, attach notes (NFRs, edge cases, decisions), create spikes and link them, and confirm acceptance criteria and DoD.
Acceptance Criteria template (copy/paste)
- Functional: user can ____, given ____, when ____, then ____.
- Validation: form rules, server validation, error handling states.
- NFR: performance (p95, throughput), security (authz, OWASP), accessibility (WCAG 2.1 AA), availability/rollback.
- Observability: logs, metrics, traces, dashboards, alerts.
- Data: migrations, backfills, idempotency, PII handling.
- Edge cases: retries, timeouts, partial failures, duplicates.
Anti-patterns to avoid
- Turning story points into hours or per-person targets.
- Estimating vague epics without splitting.
- Ignoring NFRs (“we’ll harden later”).
- Anchoring on the loudest voice or the first number.
- Treating spikes as optional (“we’ll figure it out during coding”).
Handling defects and chores
Bugs and chores can be pointed if they compete with feature work for capacity. If your team uses a separate bug budget, keep it visible and explicit. Avoid hiding significant refactors under feature stories—call them out and estimate.
Remote and distributed teams
For remote teams, the facilitation matters even more. Use clear roles (facilitator, scribe), a visible backlog, a timer, and built-in chat/notes. Keep cameras optional but insist on rapid clarification loops. The shorter the feedback loop, the more consistent your estimates become.
Worked example (end-to-end)
Scenario: “Add rate limiting to the public Orders API to protect downstream systems.”
- DoR: business goal (protect from abuse), thresholds (100 req/min per token), error shape (429 + Retry-After), observability (dashboards + alerts), rollout (per-tenant flag).
- Unknowns: gateway plugin compatibility, dynamic tenant rules, side effects on mobile clients.
- Spike (3–5 pts): PoC with gateway plugin; measure latency impact; validate burst behavior.
- Stories:
1) Introduce middleware + config model (5).
2) Implement per-tenant rules + persistence (8).
3) Observability (dashboards + SLO alerts) (3–5).
4) Rollout with canary + feature flags (3).
- NFRs: p95 latency increase < 20ms, error budget unaffected, security policy unchanged.
- Outcome: predictable rollout with small, testable increments and clear success metrics.
Turning estimates into a delivery forecast
Once stories are sized, sequencing matters. Group by dependency chain and value, then build a thin vertical path to production. Use velocity bands (e.g., 30–36 pts) to produce a range forecast. Re-forecast after each sprint review—this keeps stakeholders confident without pretending you have perfect knowledge up front.
Using GoAgile for technical estimation
GoAgile makes the flow simple: create a session, import Jira issues, select the Fibonacci deck, and start voting. Use the timer to keep focus, reveal votes together, discuss outliers, and revote if needed. After consensus, sync story points to Jira in one click. Save notes on NFRs and risks so context is never lost.

You can also run a quick spike-only session to size discovery work for the next sprint. The voting history helps you compare how your team sizes similar patterns over time.
Conclusion
Great technical estimation is a habit: prepare well, discuss openly, measure outcomes, and iterate. Use story points for relative size, spikes for uncertainty, NFRs for quality, and your own history to inform expectations. With a lightweight playbook and the right facilitation, your estimates will become fast, consistent, and trusted—exactly what high-performing Agile teams need.